

La inteligencia artificial está dejando de ser algo exclusivo de grandes empresas y servidores en la nube. Hoy día, es posible instalar y usar modelos como DeepSeek directamente en tu ordenador a través de herramientas de terceros. Eso sí, antes de lanzarte a descargar archivos y ejecutar comandos, es importante entender qué implica este proceso, qué requisitos necesita tu equipo y cuál es la mejor opción según tu nivel de experiencia.
¡SUSCRIBETE A NUESTRO NEWSLETTER!
Cada semana mandamos un único e-mail con el resumen de las noticias a +4.000 suscriptores.
Lo que debes saber antes de empezar
DeepSeek es un modelo de inteligencia artificial que, en su versión completa, requiere una potencia de cálculo enorme. Para hacerlo accesible a usuarios comunes, existen versiones reducidas, como es el caso DeepSeek-R1-8B, que ocupa 4,7 GB, frente a los más de 400 GB que ocupa el modelo completo, si bien han logrado compactarlo a poco más de 100 GB. Estas versiones son más ligeras y pueden funcionar en ordenadores menos potentes, aunque con algunas limitaciones.

Por un lado, este tipo de versiones tienen un conocimiento limitado y no se actualizan en tiempo real. Su conocimiento está congelado en la fecha de su entrenamiento, generalmente hasta 2023. Eso por no hablar de que su capacidad es menor en comparación con las versiones completas, en tanto que no alcanza la misma profundidad ni precisión en tareas complejas. Otra limitación importante, aunque también es su principal ventaja, es que funciona totalmente offline, por lo que no puede buscar información en la web ni acceder a datos en tiempo real.
A pesar de sus limitaciones, y bajo mi propia experiencia, el modelo en cuestión es bastante útil para tareas que impliquen generación de textos simples, como correos electrónicos o resúmenes, resolver problemas matemáticos o lógicos básicos, y practicar prompts en español, aunque tiende a priorizar el inglés en sus respuestas. Esta es la razón por la que deberemos indicarle el idioma en el que queramos que responda cada cierto tiempo.
¿Cuáles son los requisitos mínimos para ejecutar DeepSeek?
Aunque la versión recortada de DeepSeek baja bastante el listón en lo que a requisitos mínimos se refiere, no cualquiera equipo puede ejecutarlo con la soltura que merece. En mi MacBook Pro de 2017, por ejemplo, es prácticamente inviable: tarda más de 10 minutos en generar una simple respuesta presentándose. Se trata de un ordenador con procesador Intel Core i5 de séptima generación con dos núcleos, tarjeta gráfica integrada y apenas 8 GB de RAM.
Con todo esto en mente, asegúrate de que tu ordenador cumple con los siguientes requisitos:
Hardware
- Procesador: Un CPU de 4 núcleos o superior (Intel i5 o equivalente).
- RAM: Mínimo 8 GB (recomendado 16 GB para mayor fluidez).
- Almacenamiento: Al menos 10 GB de espacio libre (para la versión 8B).
- Tarjeta gráfica: No es obligatoria, pero una GPU compatible con CUDA acelerará el rendimiento.
Software
- Sistema operativo: Windows 10/11, macOS 10.15 o superior, o una distribución reciente de Linux.
- Herramientas adicionales: Python 3.8 o superior (para Ollama) y un navegador actualizado (para LM Studio).
Si no cumple con ninguno de estos requisitos, olvídate de intentarlo, la generación de respuestas será tan lenta y consumirá tantos recursos que dejará tu ordenador inutilizable durante varios minutos.
Método 1: LM Studio (la opción visual, ideal para principiantes)
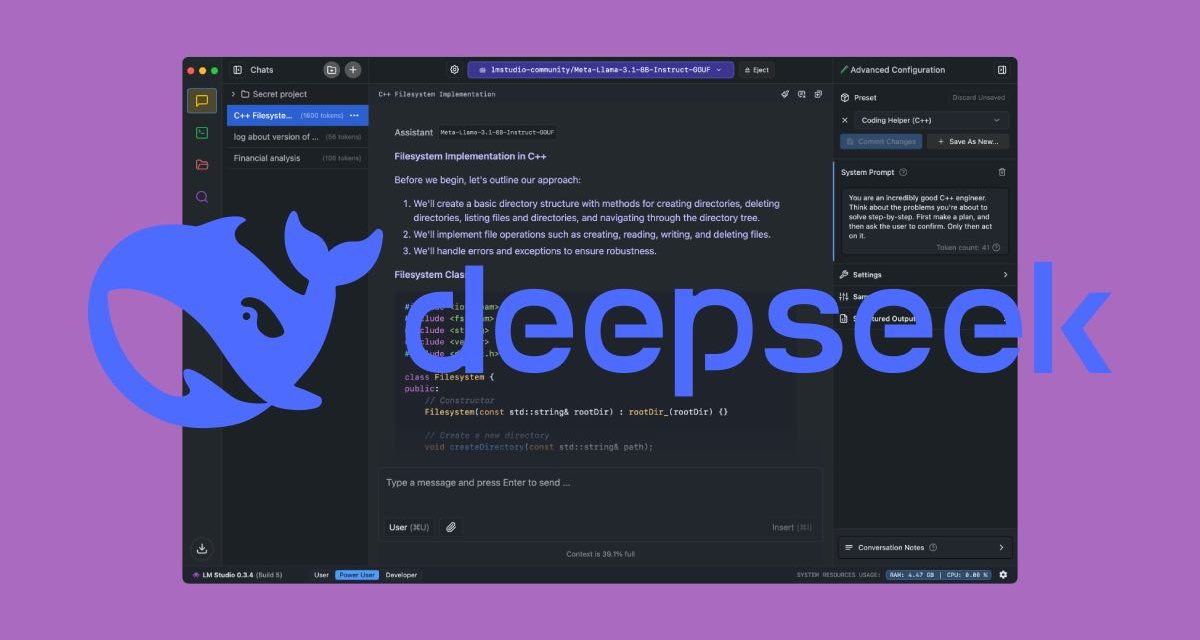
LM Studio es como tener una «tienda de aplicaciones» para modelos de IA. La interfaz gráfica del programa nos permite deshacernos completamente de comandos, haciendo el proceso accesible incluso si nunca has tocado una terminal. Para ello, entra en lmstudio.ai, haz clic en Download y selecciona tu sistema operativo (Windows, macOS o Linux). Instálalo como cualquier programa: sigue los pasos del asistente sin modificar opciones avanzadas.

Una vez instalado, abre LM Studio y dirígete a la pestaña Discover (icono de lupa en la barra izquierda). En el buscador, escribe «deepseek-r1», tras lo cual se mostrarán diferentes versiones:
- DeepSeek 8B: la más ligera (4,7 GB), recomendable para ordenadores con 8 GB de RAM.
- DeepSeek 67B: requiere 16 GB de RAM y 40 GB de espacio.
Tras elegir la versión que más se adapte a tus especificaciones y requisitos, haz clic en Download junto a «deepseek-r1-8b». La descarga empezará automáticamente. Ten en cuenta que el modelo se guarda en la siguiente ruta:
C:\Users\[tu_usuario]\AppData\Local\lm-studio(Windows) o~/.cache/lm-studio(macOS/Linux)
Si prefieres otra ubicación, dirígete a Settings y Model Settings para cambiar la carpeta predeterminada. Con el modelo instalado, navega a la pestaña Local Models (icono de carpeta), selecciona deepseek-r1-8b y haz clic en Load Model. A continuación, verás un indicador morado en la parte superior cuando esté listo. Finalmente, pulsa sobre la pestaña Chat y escribe tu pregunta en el cuadro inferior. Por ejemplo:
"Traduce al inglés la siguiente frase: 'El aprendizaje automático está revolucionando la medicina.' Además, explícame en dos líneas qué es un modelo destilado." Tras presionar Enter, verás tres indicadores:
- Pensando: tiempo de procesamiento inicial.
- Generando: la inteligencia artificial está escribiendo la respuesta.
- Tokens/s: velocidad de generación, normalmente entre 5 y 15 en procesadores antiguos y hasta 30 con tarjetas gráficas dedicadas.
Otra de las ventajas de LM Studio es que todos los diálogos se guardan automáticamente en Chat History, en el icono de reloj. También puedes crea configuraciones personalizadas en las que configurar aspectos como la temperatura del modelo o la longitud máxima de respuesta, mediante el apartado Model Settings. Por si fuera poco, permite integrar el modelo en aplicaciones externas mediante una dirección local, como http://localhost:1234.
Método 2: Ollama (para usuarios avanzados que prefieren la terminal)
La segunda opción, prácticamente igual de sencilla, pero algo más engorrosa de interactuar, recibe el nombre de Ollama. Esta herramienta de código abierto opera desde la línea de comandos, lo que nos obliga a ejecutar la terminal para acceder a DeepSeek o cualquier otro modelo que decidamos instalar. En este sentido, es más flexible que LM Studio, si bien requiere familiaridad con terminales como PowerShell o Bash.
Para instalar el programa, accede a la dirección ollama.com, descarga el instalador para tu sistema operativo y ejecútalo como cualquier otra aplicación. Al igual que LM Studio, no necesitas cambiar opciones predeterminadas. Seguidamente, abre tu terminal, la cual puedes encontrar de la siguiente manera:
- Windows: busca PowerShell en el menú Inicio.
- macOS: abre Terminal desde Spotlight (Comando + Espacio).
- Linux: Usa Control + Alt + T o busca Terminal.
Con la aplicación abierta, cuya interfaz es inexistente —no se ejecutará ninguna ventana al uso, salvo a través de la terminal—, escribe el siguiente comando y presiona Enter:
ollama pull deepseek-r1:8b La descarga comenzará. Verás un progreso en porcentaje y velocidad de descarga (ej.: 3.45 GB / 4.7 GB [=====================>-------] 73% 12 MB/s). Una vez finalizada la descarga, escribe:
ollama run deepseek-r1:8b Verás el mensaje:
>>> Send a message (/? for help), indicando que el modelo está listo.
Finalmente, escribe tu prompt. Por ejemplo:
Genera una lista de 5 libros similares a 'Cien años de soledad' con una breve sinopsis. Responde en español. 
La inteligencia artificial mostrará primero su razonamiento interno entre etiquetas <think>, luego la respuesta final. Para interactuar con el modelo, puedes recurrir a diferentes comandos, como los que se indican a continuación:
/?: Muestra todos los comandos disponibles./bye: Cierra la sesión actual y vuelve a la terminal./set history: Activa/desactiva el guardado de historial (útil para prompts sensibles)./load [nombre]: Cambia a otro modelo ya descargado (ej.:/load llama2:13b).-
--verbosepara ver métricas detalladas de rendimiento (ej.:ollama run deepseek-r1:8b --verbose).
A partir de este punto, siempre deberás ejecutar Ollama para invocar a DeepSeek. Por suerte, el programa incluye una opción para arrancarse automáticamente cuando se inicia el sistema. Por otro lado, si cierras la terminal, el modelo seguirá activo. Para detenerlo, deberás escribir el siguiente comando:
ollama stopPor último, el programa se integra también con cualquier API local a través de la dirección http://localhost:11434, ya sea para ejecutar scripts de Python o herramientas como Postman.
Problemas comunes de DeepSeek en local (y cómo solucionarlos)
El hecho de que DeepSeek se ejecute localmente no exime a la herramienta de sufrir algún que otro error puntual. Tras haberlo probado durante todo un fin de semana, estos son los tres problemas más comunes:
- El modelo no responde en español: añade siempre
Responde en españolal final de tu prompt. En Ollama, usa el flag--language esal ejecutar cualquier comando:
ollama run deepseek-r1:8b --language es- Respuestas demasiado cortas: en LM Studio, ve a Model Settings y aumenta Max Tokens (ej.: 1500). En Ollama, escribe
/set parameter num_ctx 2048para duplicar el contexto. - Errores de memoria: cierra otras aplicaciones. En Windows, ejecuta Ollama como administrador (botón derecho y Ejecutar como administrador).





excelente es un trabajo
ya quiero descargalo